红熊核心技术概述
红熊核心技术
红熊不仅开发了人工智能大模型应用中台,也结合了后端即服务(Backend as Service)和 LLMOps(Large Language Model Operations)的理念,旨在帮助开发者快速搭建生产级的生成式 AI 应用。我们在底层中构建了私有化多模态大模型,该大模型拥有独特的多模态思维框架、人类最强反馈强化学习技术(RLHF)和检索增强生成技术(RAG)。
一、多模态思维链框架
1. 背景
大型语言模型(LLMs)通过利用一步一步思考的思维链(CoT)在自然语言处理任务中展现出令人印象深刻的性能。将LLMs扩展为具有多模态能力是最近的研究热点,但这种扩展会产生高昂的计算成本并需要大量硬件资源。为了解决这些挑战,我们提出了KAM-CoT,这是一个集成了CoT推理、知识图谱(KGs)和多模态的框架,以全面理解多模态任务。KAM-CoT采用两阶段的训练过程,通过KG基础生成有效的原因和答案。通过在推理过程中结合来自KG的外部知识,模型能够更深入地理解上下文,减少幻觉并提高答案的质量。这种知识增强的CoT推理使模型能够处理需要外部上下文的问题,提供更为明智的答案。实验结果显示,KAM-CoT优于最先进的方法。在ScienceQA数据集上,我们实现了93.87%的平均准确率,超过了GPT-3.5(75.17%)18%和GPT-4(83.99%)10%。值得注意的是,KAM-CoT在同一时间内仅使用了280M可训练参数,显示了其成本效益和有效性。
2. 多模态思维链框架解决的问题
多模态思维链框架主要解决了增强语言模型(LLMs)的多模态能力,以及提高这些模型的推理质量和答案质量的问题。为此,我们提出了KAM-CoT方法,即知识增强的多模态链式思维推理方法。该方法结合了语言、视觉和知识图谱等多模态信息,并通过链式思维推理过程生成合理的答案。同时,我们还探讨了如何有效地融合这些模态,并利用知识图谱提高模型的推理能力和答案质量。实验结果在ScienceQA数据集上证明了该方法的有效性和优越性。
3. 解决的方法
红熊提出了一种基于知识图谱的问答系统方法,主要包括两个部分:子图提取和知识推理。
- 子图提取:该方法从ConceptNet中为每个样本提取一个子图。首先,将ConceptNet中的关系分为17种不同的类型,这些关系可以是正向或反向,总共有34种可能的边类型。然后,将这些三元组转换为句子,并存储相应的句子模式。这些模式用于从问题、上下文和答案选项中提取节点。子图由以下三部分组成:
- V,一个节点集;
- E,一个边集;
- ϕ,一个函数,它将每条边映射到0到33之间的一个整数,表示边类型。
知识推理:该方法使用知识推理来选择正确的答案。给定问题和k个答案选项,任务是选择正确的选项。该方法首先将问题与上下文和答案选项进行比较,以确定它们之间的关系。然后,使用这些关系构建一个子图,该子图连接了问题中的所有节点。为确保子图的有效性,方法遵循了Yasunaga et al. (2021)中的修剪策略,为每个样本保留最多200个节点。最后,方法使用子图进行训练和推理,以确定正确的答案选项。
4. 创新点
提出KAM-CoT模型:提出了KAM-CoT(Knowledge Augmented Multimodal Chain of Thought)模型,这是一个知识增强的多模态链式思维推理模型,旨在增强语言模型的推理能力和答案质量。
- 多模态融合:KAM-CoT模型利用了语言上下文、视觉特征编码器和图神经网络(GNN)等多种模态,以全面理解多模态任务。这些模态通过一系列的融合机制整合在一起,使机器能够像人类一样进行连贯的思维和推理。
- 两阶段推理过程:与传统的单一推理过程不同,KAM-CoT将推理过程分为两个阶段。第一阶段生成合理化的推理,第二阶段将这些推理作为额外输入,提供最终答案。分阶段推理过程有助于提高答案的准确性和合理性。
- 知识图谱的利用:模型利用知识图谱(KG)增强多模态推理。知识图谱的融入减少了语言模型在推理过程中产生的幻觉,提高了答案的准确性。
- 高效融合机制:模型探索了多种可能的模态融合机制,提高了不同模态之间的信息交换效率。这些机制有助于提高模型的性能和效率。
- 跨大规模模型的扩展性:虽然论文中的模型在较小参数规模下取得显著性能,但未来可以探索如何将该模型扩展到更大的模型,如LLaMA家族。这种扩展使模型能够处理更复杂、更广泛的问题。
- 具体知识密集型领域的整合:未来工作还可进一步整合特定知识密集型领域,以提高模型的性能和实用性,使模型更好地适应特定领域任务和问题。
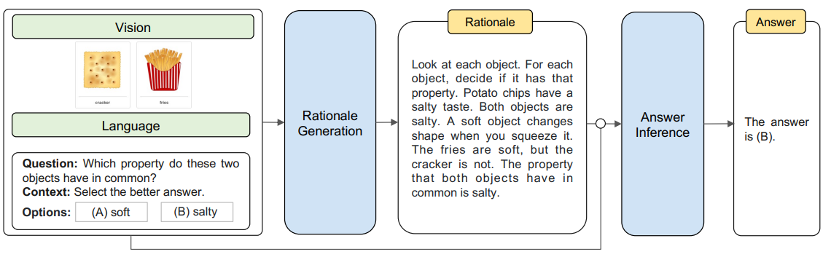
5. 实际应用价值
知识图谱构建和应用:方法可用于从大量文本数据中提取知识,构建知识图谱。对需要大规模知识的应用场景,如智能助手、智能客服等,具有重要实用价值。
- 知识问答系统:方法可用于构建知识问答系统,例如,用户提出关于某个主题的问题,系统通过查询知识图谱找到相关实体和关系,从而提供准确答案。
- 辅助教育:方法可用于辅助教育领域,帮助学生理解复杂概念或主题。通过构建相关知识图谱,清晰展示概念之间关系,帮助学生更好地理解和记忆。
- 语义搜索:在语义搜索方面,方法可用于提高搜索准确性和相关性。通过分析用户查询语义,系统找到相关实体和关系,提供更符合用户需求的搜索结果。
- 自然语言处理:方法可用于自然语言处理其他领域,如情感分析、摘要生成等。通过提取实体之间关系,对文本进行深入分析和理解,提高处理结果的准确性和可靠性。
(来源论文[2302.00923] Multimodal Chain-of-Thought Reasoning in Language Models (arxiv.org))
Here's the revised and enriched version of the provided content on "人类最强反馈强化学习技术":
二、人类最强反馈强化学习技术
1. 背景介绍
基于人类反馈的强化学习(RLHF)是一种机器学习(ML)技术,它利用人类反馈来优化 ML 模型,从而更有效地进行自我学习。强化学习技术可训练软件做出最大限度地提高回报的决策,使其结果更加准确。
RLHF 将人类反馈纳入奖励功能,使 ML 模型可以执行更符合人类目标、愿望和需求的任务。RLHF 广泛应用于生成式人工智能(生成式 AI)应用程序,包括大型语言模型(LLM)。
2. 为什么 RLHF 很重要?
人工智能(AI)应用范围广泛,从自动驾驶汽车到自然语言处理(NLP)、股票市场预测器和零售个性化服务,不胜枚举。无论给定的应用程序是什么,人工智能的最终目标都是模仿人类的反应、行为和决策。机器学习模型必须将人类输入编码为训练数据,以便人工智能在完成复杂任务时更接近人类。
RLHF 是一种特殊技术,用于与其他技术(例如有监督学习和无监督学习)一起训练人工智能系统,使其更加人性化。首先,将模型的响应与人类的响应进行比较。然后,人类会评测不同机器响应的质量,对哪些响应更人性化进行评分。评分基于人类的内在品质,例如友善、适当程度的情境化和心情。
RLHF 在自然语言理解方面表现得非常突出,但也可用于其他生成式人工智能应用程序。
2.1 增强人工智能性能
RLHF 使机器学习模型更加准确。您可以训练模型,使其根据预生成的人类数据进行训练,但增加额外的人工反馈回路可以显著提高模型性能。
例如,当文本从一种语言翻译成另一种语言时,模型生成的文本可能在技术上是正确的,但对读者而言听起来并不自然。专业译员可以先进行翻译,并对机器生成的翻译评分,然后对一系列机器生成的翻译进行质量评分。通过对模型进行进一步训练,可以更好地生成听起来自然的翻译。
2.2 引入复杂的训练参数
在某些情况下,生成式人工智能可能很难针对某些参数准确地训练模型。例如,如何定义一首音乐的情绪? 可能有一些相关技术参数,例如音调和节奏,可以表明某种情绪,但是音乐作品的精神相比一系列技术性细节而言要更加主观,定义也不太明确。您可以提供人工指导,让作曲家创作各种情绪的作品,然后根据情绪水平对机器生成的作品进行标记。这使机器能够更快速地学习这些参数。
2.3 提高用户满意度
尽管机器学习模型可能很准确,但可能与人类相去甚远。这时便需要 RL 来引导模型,为人类用户提供最具吸引力的最佳响应。
例如,如果您问聊天机器人外面的天气怎么样,它可能会回答“30 摄氏度,多云,湿度高”,或者也可能会回答“目前温度在 30 度左右。阴天潮湿,比较闷热!”尽管两个答案相似,但第二个听起来更自然,提供了更多上下文信息。
当人类用户就他们喜欢哪种模型的响应进行评分时,您可以使用 RLHF 来收集人类反馈并改进模型,以便更好地为真正的人类提供服务。
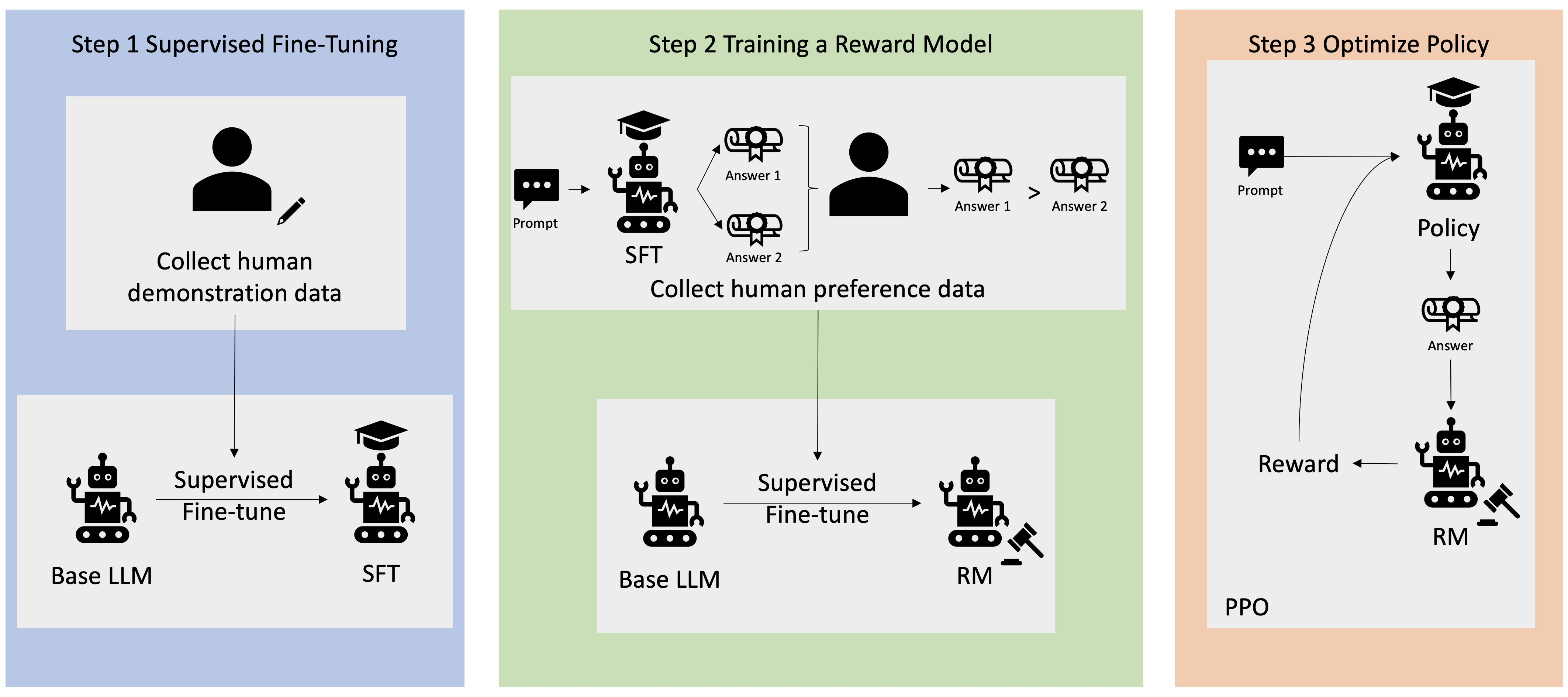
3. RLHF 如何运作?
RLHF 分四个阶段执行,然后模型才准备就绪。在此,我们以语言模型(公司内部知识库聊天机器人)为例,该模型使用 RLHF 进行完善。
我们简单概述一下学习过程。训练模型及其针对 RLHF 的策略优化存在巨大的数学复杂性。但是,这些复杂过程在 RLHF 中有明确定义,并且通常有预构建的算法,只需要您的特定输入即可。
3.1 数据收集
在使用语言模型执行机器学习任务前,会为训练数据创建一组人工生成的提示和响应。这组提示和响应将在模型的后期训练过程中使用。
例如,提示可能是:
- “Where is the location of the HR department in Boston?”
- “What is the approval process for social media posts?”
- “What does the Q1 report indicate about sales compared to previous quarterly reports?”
然后,公司的知识型员工会以准确、自然的响应回答这些问题。
3.2 对语言模型进行监督式微调
您可以使用商业预训练模型作为 RLHF 的基础模型。随后使用检索增强生成(RAG)等技术根据公司的内部知识库对模型进行微调。对模型进行微调时,您可以将其对预定提示的响应与上一步中收集的人工响应进行比较。数学方法可以计算出两者间的相似程度。
例如,可以为机器生成的响应分配介于 0 和 1 间的分数,其中 1 表示最准确,0 表示最不准确。确定好分数后,该模型便有了一项策略,即生成得分更接近人类响应的响应。此策略便是该模型未来所有决策的基础。
3.3 构建单独的奖励模型
RLHF 的核心是根据人类反馈训练单独的人工智能奖励模型,然后使用该模型作为奖励函数,通过 RL 优化策略。假设模型中有一组回答相同提示的多个响应,人类可以指出其对每个响应质量的偏好。您可以使用这些响应评分偏好来建立奖励模型,该模型会自动估计人类对任何给定提示的响应给出多高的分数。
3.4 使用基于奖励的模型优化语言模型
然后,语言模型会使用奖励模型在响应提示前自动完善其策略。使用奖励模型,语言模型可内部评估一系列响应,然后选择最有可能获得最大奖励的响应。这意味着它以优化程度更高的方式满足了人类的偏好。
下图为 RLHF 学习过程的概述:+
4. RLHF 在生成式人工智能领域有哪些应用?
RLHF 是公认的确保 LLM 制作真实、无害且有用的内容的行业标准技术。但是,人类沟通是一个主观的创造性过程,而 LLM 输出的有用性则深受人类价值观和偏好的影响。每个模型的训练方式都略有不同,所用的人类响应者也不尽相同,因此即使是竞争力相当的 LLM,输出也会有所差异。每个模型涉及人类价值观的程度完全取决于创建者。
RLHF 的应用超出了 LLM 的范围,扩展到了其他类型的生成式人工智能。下面是一些示例:
- RLHF 可用于 AI 图像生成:例如衡量艺术品的现实性、技术性或意境
- 在音乐生成中,RLHF 可以帮助创作与活动的特定情绪和音轨相匹配的音乐
- RLHF 可以用在语音助手中,引导语音,使其听起来更友好、充满好奇、更值得信赖
Here's the revised and enriched version of the provided content on "RAG(检索增强生成)":
三、RAG(检索增强生成)
1. 什么是检索增强生成?
检索增强生成(RAG)是对大型语言模型(LLM)输出进行优化的技术,使其能够在生成响应之前引用训练数据来源之外的权威知识库。大型语言模型用海量数据进行训练,使用数十亿个参数生成回答问题、翻译语言和完成句子等任务的原始输出。在 LLM 本就强大的功能基础上,RAG 扩展了其能力,使其能访问特定领域或组织的内部知识库,而无需重新训练模型。这是一种经济高效的改进 LLM 输出的方法,使其在各种情境下都能保持相关性、准确性和实用性。
2. 为什么检索增强生成很重要?
LLM 是一项关键的人工智能(AI)技术,为智能聊天机器人和其他自然语言处理(NLP)应用程序提供支持。目标是通过交叉引用权威知识来源,创建能够在各种环境中回答用户问题的机器人。然而,LLM 技术的本质在其响应中引入了不可预测性,且训练数据是静态的,有其知识的截止日期。
LLM 面临的已知挑战包括:
- 提供虚假信息。
- 提供过时或通用的信息。
- 从非权威来源创建响应。
- 由于术语混淆,不同培训来源使用相同术语来谈论不同事物,导致不准确的响应。
可以将 LLM 看作是一个过于自信的新员工,他拒绝了解时事,但总是绝对自信地回答每一个问题。这种态度会对用户的信任产生负面影响,这是不希望聊天机器人效仿的。
RAG 通过重定向 LLM,从权威、预先确定的知识来源中检索相关信息,解决了这些挑战。组织可以更好地控制生成的文本输出,用户也能深入了解 LLM 如何生成响应。
3. 检索增强生成有哪些好处?
RAG 技术为组织的生成式人工智能工作带来了多项好处。
3.1 经济高效的实施
聊天机器人开发通常从基础模型开始。基础模型(FM)是在广泛的广义和未标记数据上训练的 API 可访问 LLM。重新训练 FM 以包含组织或领域特定信息的计算和财务成本很高。RAG 是一种将新数据引入 LLM 的更经济高效的方法,使生成式人工智能技术更广泛地被获得和使用。
3.2 当前信息
即使 LLM 的原始训练数据来源适合您的需求,保持相关性也具有挑战性。RAG 允许开发人员为生成模型提供最新的研究、统计数据或新闻。他们可以使用 RAG 将 LLM 直接连接到实时社交媒体提要、新闻网站或其他经常更新的信息来源,使 LLM 向用户提供最新信息。
3.3 增强用户信任度
RAG 允许 LLM 通过来源归属呈现准确的信息。输出可以包括对来源的引文或引用。用户可以自己查找源文档以进一步说明或获得更详细的信息,从而增加对生成式人工智能解决方案的信任和信心。
3.4 更多开发人员控制权
借助 RAG,开发人员可以更高效地测试和改进他们的聊天应用程序。他们可以控制和更改 LLM 的信息来源,以适应不断变化的需求或跨职能使用。开发人员还可以将敏感信息的检索限制在不同的授权级别内,确保 LLM 生成适当的响应。如果 LLM 引用了错误的信息来源,他们可以进行故障排除并修复。组织可以更自信地为更广泛的应用程序实施生成式人工智能技术。
4. 检索增强生成的工作原理是什么?
如果没有 RAG,LLM 会接受用户输入,并根据它所接受训练的信息或它已经知道的信息创建响应。RAG 引入了一个信息检索组件,该组件利用用户输入首先从新数据源提取信息。用户查询和相关信息都提供给 LLM,LLM 使用新知识及其训练数据来创建更好的响应。以下各部分概述了该过程。
4.1 创建外部数据
LLM 原始训练数据集之外的新数据称为外部数据。它可以来自多个数据来源,例如 API、数据库或文档存储库。数据可能以各种格式存在,例如文件、数据库记录或长篇文本。另一种称为嵌入语言模型的 AI 技术将数据转换为数字表示形式,并将其存储在向量数据库中。这个过程会创建一个生成式人工智能模型可以理解的知识库。
4.2 检索相关信息
下一步是执行相关性搜索。用户查询将转换为向量表示形式,并与向量数据库匹配。例如,考虑一个可以回答组织人力资源问题的智能聊天机器人。如果员工搜索:“我有多少年假?”,系统将检索年假政策文件以及员工个人过去的休假记录。这些特定文件将被退回,因为它们与员工输入的内容高度相关。相关性是使用数学向量计算和表示法计算和建立的。
4.3 增强 LLM 提示
接下来,RAG 模型通过在上下文中添加检索到的相关数据来增强用户输入(或提示)。此步骤使用提示工程技术与 LLM 进行有效沟通。增强提示允许大型语言模型为用户查询生成准确的答案。
4.4 更新外部数据
下一个问题是如果外部数据过时怎么办?要维护当前信息以供检索,请异步更新文档并更新文档的嵌入表示形式。您可以通过自动化实时流程或定期批处理来执行此操作。这是数据分析中常见的挑战,可以使用不同的数据科学方法进行变更管理。
下图显示了将 RAG 与 LLM 配合使用的概念流程:
5. 检索增强生成和语义搜索有什么区别?
语义搜索可以提高 RAG 结果,适用于想要在其 LLM 应用程序中添加大量外部知识源的组织。现代企业在各种系统中存储大量信息,例如手册、常见问题、研究报告、客户服务指南和人力资源文档存储库等。上下文检索在规模上具有挑战性,因此会降低生成输出质量。
语义搜索技术可以扫描包含不同信息的大型数据库,并更准确地检索数据。例如,他们可以回答诸如“去年在机械维修上花了多少钱?”之类的问题,方法是将问题映射到相关文档并返回特定文本而不是搜索结果。然后,开发人员可以使用该答案为 LLM 提供更多上下文。
RAG 中的传统或关键字搜索解决方案对知识密集型任务产生的结果有限。开发人员在手动准备数据时还必须处理单词嵌入、文档分块和其他复杂问题。相比之下,语义搜索技术可以完成知识库准备的所有工作,因此开发人员不必这样做。它们还生成语义相关的段落和按相关性排序的标记词,以最大限度地提高 RAG 有效载荷的质量。